Organizations must develop an effective data pipeline process to manage data sources, flow, and quality.
Overview of a Data Pipeline
A data pipeline refers to the steps and processes used to manage data from its origin to its destination. This includes data ingestion, transformation, and delivery to a data storage location or end user. It is critical to get everything right because organizations often create and build applications and microservices that depend on the same data pipeline process.
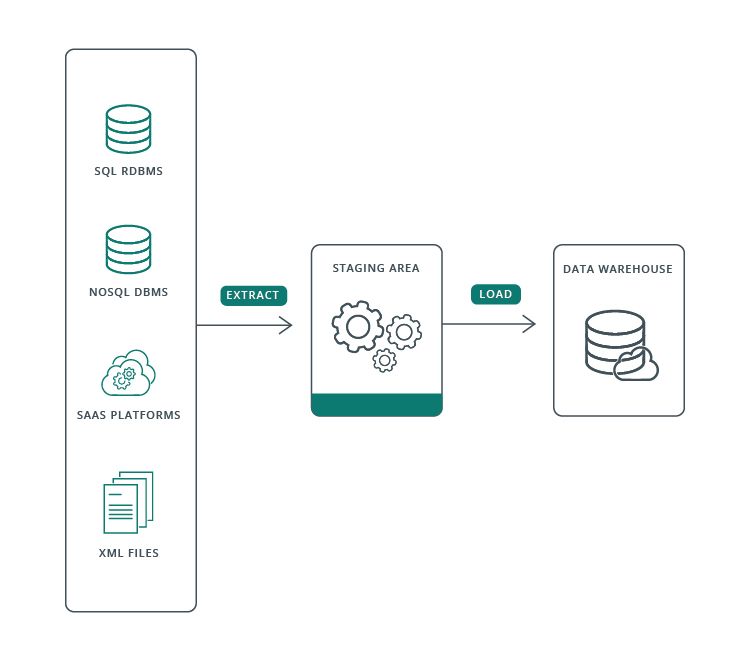
(Image source: Qlik.com)
Below are 8 data pipeline basics to help ensure a successful data management process.
Treat the data pipeline as a project
Like any project, data pipelines should have clear requirements and goals, as well as a project plan and timeline. This includes data sources, data flow, data storage location, data cleansing and transformation needs, data access requirements, and data delivery processes.
Assess data requirements
Determine data sources, data flow and dependencies, data storage needs, data access requirements, data delivery processes, data quality, and data governance requirements. Some questions to explore include the following:
Who are the data users?
• What data do they need and how should it be processed and delivered?
• Does the data need to be cleansed and transformed?
• What data storage and data access requirements are necessary?
Configure, not code
Data pipeline tasks such as data ingestion, transformation, and delivery should be configured rather than coded. This allows for greater flexibility in data pipeline management and reduces development time. To get this right, consider limiting coding to high-complexity tasks and data sources that require custom coding.
Minimize data centers of gravity
Data should flow from its source to the data warehouse or data lake with minimal manipulation. To reduce data processing errors and improve data quality look for ways to consolidate your data infrastructure. For example, eliminating platform diversity and reducing the number of enterprise data platforms can significantly increase your IT throughput per business dollar spent.
Maintain clear data lineage
Data lineage refers to the data’s origins, transformations, and usage throughout the pipeline. Maintaining data lineage is critical for data governance and compliance and quality management. For example, fields are continuously added and deprecated. Failure to maintain a clear data lineage can result in data processing errors and data integrity issues.
Implement data pipeline checkpoints
You should build regular data quality checks into the data pipeline process. These data pipeline checkpoints can help catch data processing errors, data quality issues, and data cleansing and transformation opportunities.
Componentized data ingestion pipelines
Consider data ingestion pipelines as modular components to provide flexibility and agility in data pipeline management. This allows data ingestion processes to be easily added, modified, or removed as data sources and data requirements change.
Maintain data context
Data context refers to data attributes, relationships, quality, lineage, and usage. Maintaining data context helps ensure data quality and data integrity throughout the data pipeline process.
Data pipelines are essential for data management but require careful planning and ongoing maintenance to ensure successful data delivery. At Expeed, we offer data solutions and services for enterprises to streamline their data pipeline processes. Our team of data experts can help you assess data requirements, configure data pipelines, and implement data quality checks to ensure successful data management. Contact us to learn more about how we can support your data pipeline needs.

Expeed Software is a global software company specializing in application development, data analytics, digital transformation services, and user experience solutions. As an organization, we have worked with some of the largest companies in the world, helping them build custom software products, automate processes, drive digital transformation, and become more data-driven enterprises. Our focus is on delivering products and solutions that enhance efficiency, reduce costs, and offer scalability.

AI-Powered Data Management: How Microsoft Copilot Enhances Data Governance and Analytics
June 12, 2025

Solving DateTime Issues Between Micronaut and JavaScript Using ISO 8601
June 20, 2025

Secure AI Gateways: The Smarter Alternative for Enterprises Seeking AI Control, Security, and Impact
June 24, 2025