
Businesses are discovering custom machine learning solutions to fill the void in them, racing towards market success, much like finding that missing piece of a puzzle. As the integration of machine learning for business continued to push companies towards achieving a higher return on investment, more companies began to embrace this innovative trend. Finding focused solutions to specific problems and harnessing the power of data generated by predictions and insights paid off big time for the software industry. This guide will walk you through the process of developing a custom ML solution.
Custom Machine Learning Solutions

By 2029, we expect the machine learning market to grow exponentially to $209.91 billion. More organizations are clearly relying on technology, expecting rapid growth and customized solutions. A significant benefit of machine learning solutions is that they reduce the pressure behind decision-making in the business sector and save organizations from running into avoidable hurdles. Mostly when the size of data sets exceeds the human comprehensible form, machine learning steps in to ease the burden. Advanced technologies leverage these data sets for deep analysis, yielding valuable insights that guide businesses.
People often confuse the terms machine learning, artificial intelligence, and data science. This is due to the distinct roles that each of these sectors plays in propelling a business towards success. Machine learning can be defined as a derivative of artificial intelligence (AI) that can learn from continuous feeds of data, managing to make automated decisions. To implement machine learning, one does not need to sit and write intricate programming codes.
Why a custom machine learning solution?
Today, data reigns supreme in the business world. This makes data-driven decisions an inevitable factor in the race towards success. Though traditional solutions offer results, custom machine solutions intend to focus more on solving issues in a personalized manner. Let us see how a custom machine learning solution benefits businesses.
Personalized Solutions: Challenges vary according to the niche of businesses. Hence, a traditional machine learning solution won’t be an ultimate solution for every business. This is where AI-powered custom machine learning solutions enter. Such personalized solutions can easily fit into an organization’s structure, addressing the key issues on the go.
Multi-functional systems: Custom machine learning solutions can leverage AI to build solutions to a diverse set of problems, making it an all-in-one answer to key organizational issues.
Competitive Advantage: Bespoke machine learning solutions can offer insights and data that won’t be available from a traditional solution. This presents a competitive advantage to an organization to stay ahead of the curve.
Long-term cost efficiency: Custom machine learning solutions are all about improving precision on the go. Even though the initial implementation costs may be high, the tool can be very rewarding for the organization in the long run because it yields efficient results.
Enhanced Customer Experience: Personalization motivates a customer to stay loyal to an organization. By providing focused services to target customers, custom machine learning solutions will help enhance the overall customer experience.
Data Privacy and Security: While creating a customized machine learning solution, strict security measures can be adapted to safeguard sensitive organizational and customer data. This makes the tools secure and trustworthy in the market.
Developing a Custom Machine Learning Solution
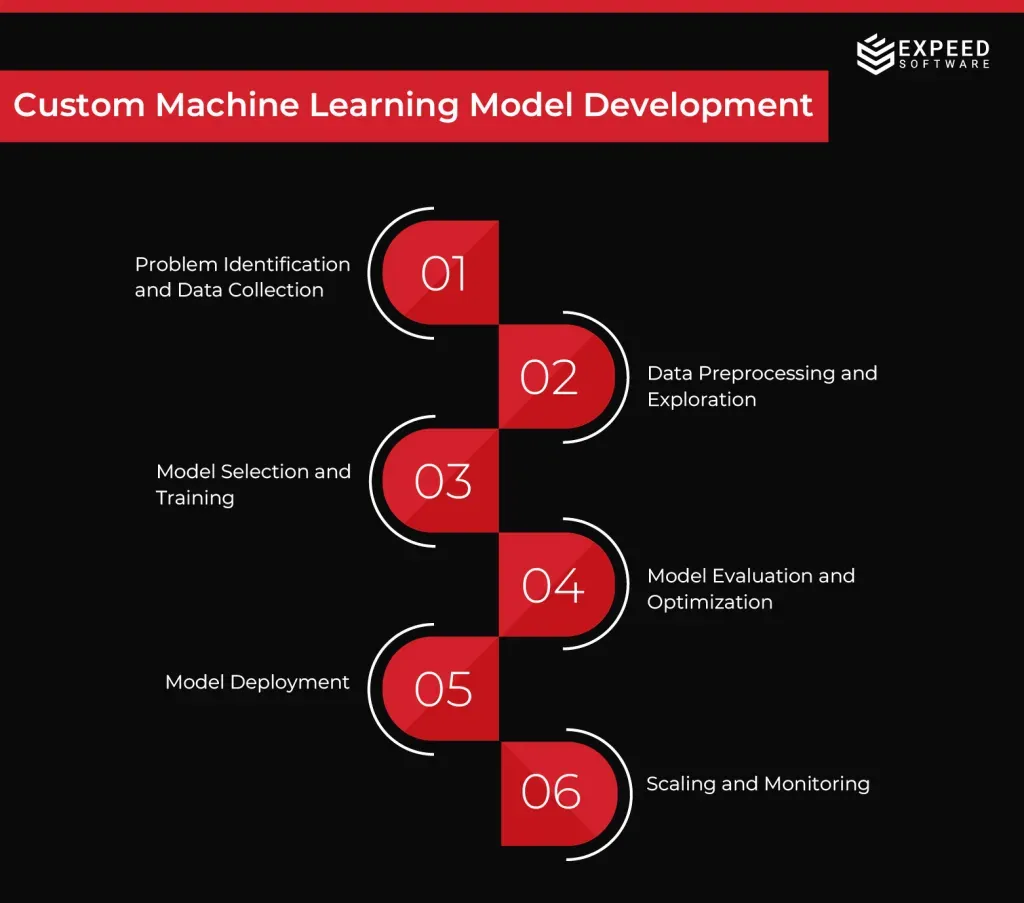
You should not implement an effective ML solution hastily. A detailed study is required to identify the need for an ML solution in an organization. The top management of an organization must identify the key problems and existing flaws before deciding to develop an AI solution to address these issues. Let’s examine the typical process of developing a customized machine learning solution for an organization.
Step #1: Identifying problems and Data Collection
The more clarity you have about the issues at hand, the better you can plan the AI solution for problem solving. Explore business-specific needs and hold comprehensive meetings to develop a detailed plan for how to handle them. Developers can then review the prepared action plan to determine how AI can aid in resolving the issues.
The stakeholders can create a preliminary plan for the implementation of the machine learning solution by finding answers to the following questions.
Q1. What are the key objectives of your business? Identify how an AI solution can contribute towards achieving the selected objectives
Q2. If not an ML solution, how else can you fix this problem? Does implementing an ML solution escalate the problem-solving process compared to a traditional approach?
Q3. What could be the apt algorithm that can help you handle the persisting issue?
Q4. How are the organizational goals defined, and how can the ML solution’s performance be measured?
Q5. How can you implement transparency in the ML solution?
Q6. What are the expected inputs and outputs?
Q7. How can the implementation of the custom ML solution align with the company’s ethical standards?
Q8. What are the effective methods to determine accuracy, precision and confusion metrics?
After establishing the business needs, the next step is to gather data for training the ML model. Gathering up a huge heap of data won’t help you much. Not quantity but quality of data helps the ML model be efficient. Make sure that the collected data sets are clean and well structured.
Step #2: Data Pre-processing and Exploration
After collecting and appropriately structuring the required data, the next step is to prepare the data for training the model. You can split the data preprocessing into the following steps:
- Data collection
- Data cleansing
- Data aggregation
- Data augmentation
- Data labeling
- Normalization and transformation
The above-listed steps can vary depending on the nature of the data collected to train an ML model. Though these steps might gnaw out a big chunk of your time, it will be well worth the effort.
Once you have collected the required data from various sources, structure it appropriately to normalize it. During this process, it is crucial to remove any incorrect data or identify any missing data sets to ensure precision during processing. If the accumulated data contains sensitive or personal information, you can also ensure its anonymity. After structuring the data sets properly, you can split them into training, test and validation sets.
Step #3: Model Selection and Training
After completing the data processing, it’s time to train the AI model using the appropriate algorithms and techniques. Selecting the appropriate algorithm that aligns with your organization’s objectives is crucial. One popular method for mapping variables in a data set is linear correlation. This is where hyperparameters step into the picture.
Hyperparameters are settings that control the structure and training process of the model. We don’t obtain this from the data fed during the process. Hyperparameter tuning can be done by grid search, random search, Bayesian optimization or manual tuning. Once you identify the feature that provides the best results, you can develop ensemble models for performance improvisations. Pick the model that yields the best result.
Step #4: Model Evaluation and Deployment
The model evaluation process helps you determine the efficiency of the custom machine learning model. You can evaluate the model using a validation data set. Confusion matrix values are helpful in problem classification. You can check the efficiency of the model by comparing the predicted values with the actual values in a confusion matrix. If you find any anomalies, you can adjust the hyperparameters further. To get a better analysis, you can compare the results generated by this custom ML model to those of a heuristic model.
Step #5: Model Deployment
Once you are satisfied with the developed ML model’s performance, it’s time to evaluate its real-world performance. Deploy the model and begin monitoring its performance to operationalize it. Adopt continuous iterations to continuously improve the performance of the ML model. The deployment or operationalization of the ML model comprises the following steps:
- Model versioning
- Model iterations
- Deployment
- Monitoring
Step #6: Scaling and Monitoring
Despite the deployment and constant monitoring of the model, there is always room for its expansion. The flexible world of technology and businesses requires scaling the model to make it more adaptable and efficient.
After understanding the business progress, create a set of requirements and incorporate them into the model. Challenge the model’s functionality by expanding it. To explore different deployment scenarios, identify the appropriate operational requirements.
Final Word
Once deploying a custom machine learning model, always look out for three things: what worked, what didn’t, and what needs improvement. Intelligent solutions that satisfy both producers and consumers now dominate the market. This is what gives machine learning and artificial intelligence solutions their prime importance. Unlike traditional solutions, custom ML solutions aim at the set of handpicked problems in an organization and work out remedies to neutralize the hassles. Each step listed out in this guide is important in building an efficient machine learning solution. A well-planned and properly developed machine learning model can drive your business toward unprecedented potential.